執筆者:Handbook編集部
再アノテーションの実施
はじめに
この記事では、Labelbox を用いてアノテーション作業を行う際、再アノテーションを実施するために使用できるフィルターなどの機能の説明を記載しています。
通常、アノテーションは一度実施して終了ではありません。モデル開発の結果、アノテーションの仕様や条件を見直すことがあります。再アノテーションを繰り返して、アノテーション品質の向上、モデル精度のアップを行います。
再アノテーションを行う前に、フィルタリングや Similarity Search の機能をうまく使ってラベリングできていないデータを見つけると、効率的に再アノテーションを行えます。
フィルタリング機能
- Catalog に移動します。
- 左上の【Create a serach query】を押下し、目的に沿ったフィルターをかけます。
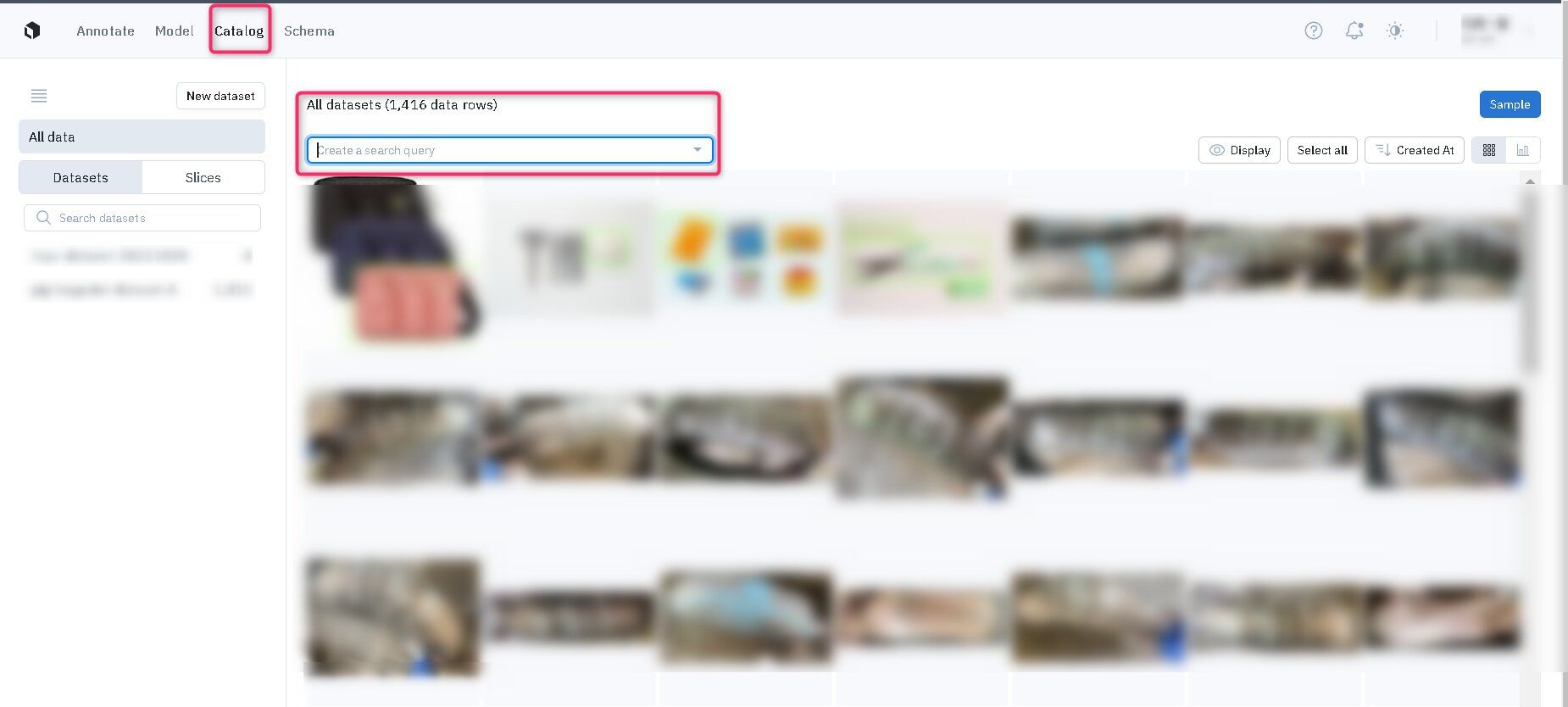
Catalog で使用できる検索・フィルター機能は以下の通りです。
| 種類 | 説明 | 例 |
|---|---|---|
| Annotation | Labelbox 上で作成された、または Labelbox にアップロードされたアノテーションにフィルターをかける | X がアノテーションされた画像を表示する |
| Predictions (coming soon) | Model run にアップロードされた予測値にフィルターをかける | モデルが X を検出した画像を表示する |
| Dataset | データ行が属するデータセットにフィルタをかける | データセット X にアップロードされたすべての画像を表示する |
| Metadata | ユーザーがアップロードしたカスタムメタデータのフィールド | 画像の撮影日時 |
| Project status | プロジェクトに関する状況 | 特定のプロジェクトに提出されていないデータ |
| Similarity functions | Function のスコアによるフィルタリング | 類似性を利用してラベリングのためのデータを探す |
| Media attributes | アップロード時に計算されるデータの属性。メディアタイプごとに異なるフィールドを持つ。 | メディアタイプ。画像、動画、テキスト、動画 |
Similarity Search による検索
Similarity Search を用いると、類似したデータを検索することができます。これにより、アノテーションするデータを絞り込めます。 検索手順は以下の通りです。
- データの右下のアイコンにカーソルを合わせてクリックするか、対象となるデータをすべて選択して【Similar to selection】を押下します。
- 自動的に類似したデータが表示されます。


検索後の再アノテーション
上記の方法で、うまくアノテーションができていないデータを検索し、再度 Batch を作成します。Batch の作成方法についてはこちらを参照してください。
Batch を作成したら、Project 内でそのデータを再度アノテーションしていきます。
このように、データを絞り込みながら、再アノテーションを繰り返すことで、効率的にアノテーションの品質を向上させることができます。
アノテーションの取得
再アノテーションの前に、アノテーションを取り出し、外部のプログラムで閲覧したり解析したい場合があります。
この場合は、 Labelbox の Export 機能を使って、アノテーションデータを取得することができます。
Export 機能を使用すると、以下のような JSON 形式でアノテーションを取得できます。
[
{
"ID": "clfc**********427s",
"DataRow ID": "************rbdt6e60l",
"Labeled Data": "https://storage.labelbox.com/cl6oj44****w%2Ff7fc6d23-470a-cb62-5db8-ccc6ca3c51cc****b9d30e53f48d_0.jpg?Expires=16****2969821&KeyName=labelbox-assets-key-3&Signature=0An4O04WgR******",
"Label": {
"objects": [
{
"featureId": "**********offlo",
"schemaId": "clfaa*********",
"color": "#ff0000",
"title": "data",
"value": "data",
"point": {
"x": 31.4,
"y": 67.0
},
"instanceURI": "https://api.labelbox.com/masks/feature/*********?token=eyJhbGc**************Ghvsy4voGirj-ml5pHDKpQ"
}
],
"classifications": [],
"relationships": []
},
"Created By": "user@email.com",
"Project Name": "project1",
"Created At": "2021-02-10T09:52:06.000Z",
"Updated At": "2021-05-25T08:12:05.000Z",
"Seconds to Label": 4.221,
"Seconds to Review": 0,
"Seconds to Create": 4.221,
"External ID": "data-6952-4b83-b1********53f48d_0.jpg",
"Global Key": null,
"Agreement": -1,
"Is Benchmark": 1,
"Benchmark Agreement": -1,
"Benchmark ID": null,
"Dataset Name": "dataset1",
"Reviews": [],
"View Label": "https://editor.labelbox.com?project=clfaa1********jf8atq&label=**********e3gk427s",
"Has Open Issues": 0,
"Skipped": false,
"DataRow Workflow Info": {
"taskName": "Done",
"Workflow History": [
{
"actorId": "*************5w0o00xv",
"action": "MOVE",
"createdAt": "2022-05-17T09:17:20.035Z"
},
{
"actorId": "cl6oj4***********v",
"action": "MOVE",
"createdAt": "2022-12-15T08:52:06.090Z",
"previousTaskId": "031*********7bdab5fe9641",
"previousTaskName": "Initial labeling task"
},
{
"actorId": "cl6o**********5w0o00xv",
"action": "MOVE",
"createdAt": "2020-11-07T09:52:06.059Z",
"nextTaskId": "03126-7bd*************b5fe9641",
"nextTaskName": "Initial labeling task"
}
]
}
}
]
以下は、Python SDK を用いた Export のコード例です。
import json
import labelbox
from labelbox import DataRow, MediaType
from labelbox.schema.data_row_metadata import DataRowMetadataField
LB_API_KEY = <Your API Key>
# Labelbox client を作成します
lb = labelbox.Client(api_key=LB_API_KEY)
# Labelbox project を取得します
project = lb.get_project(<Your Project ID>)
# アノテーションを Export します
labels = project.export_labels(download = True)
json_filename ="annotation_label.json"
with open(json_filename, 'w') as f:
json.dump(labels, f, indent=4)
Export されるアノテーションデータは、Dataset や Batch にあるアノテーションされたデータのみです。アノテーションされていないデータに関しては、Export されません。
まとめ
再アノテーションの段階では、うまくアノテーションができていないデータのみをフィルターをかけて検索し、正しくアノテーションしていきます。SImilarity search や Catalog 上でのフィルタリング機能を活用することで、効率よくアノテーションの品質を高めることができます。